

AAAI 人工智能大会(AAAI Conference on Artificial Intelligence)是国际人工智能领域重要的年度学术会议,由国际人工智能促进协会(AAAI)主办,在学术界具有广泛影响力,被CCF 列为 A 类会议。第 40 届 AAAI 人工智能大会(AAAI 2026)于 2026 年 1 月 20 日至 27 日在新加坡召开,中国科学院声学研究所噪声与音频声学实验室郑成诗研究员、李晓东研究员团队共有三项研究成果被大会录用并展示,研究方向覆盖神经声码器、音频质量评价及唇语语音合成等前沿领域。录用并在会上分享的论文包括 DegVoC: Rethinking Neural Vocoder from a Degradation Perspective,GOMPSNR: Reflourish the Signal-to-Noise Ratio Metricfor Audio Generation Tasks及SLD-L2S: Hierarchical Subspace Latent Diffusion for High-Fidelity Lip to Speech Synthesis。
1. DegVoC: Rethinking Neural Vocoder from a Degradation Perspective
声学解码是音频生成、多模态AI的核心技术之一。传统神经声码器多将任务建模为条件式生成,忽略了声学表征的退化规律与分布先验,往往需要大量算力与较高延迟才能实现高保真语音合成。针对这一问题,研究助理李安冬及郑成诗研究员、腾讯AI实验室俞栋博士等从声学退化机理出发,将声码器建模为线性退化问题,并结合优化理论提出“初始化-深度正则求解”新范式,并利用谱分层先验构建子带生成模型,通过非均匀子带分割、交互与合并,在更低参数量、更低计算复杂度、更快推理速度下,在多个公开标准数据集上取得最优生成效果,为轻量化、高效率神经声码器设计提供了全新思路。
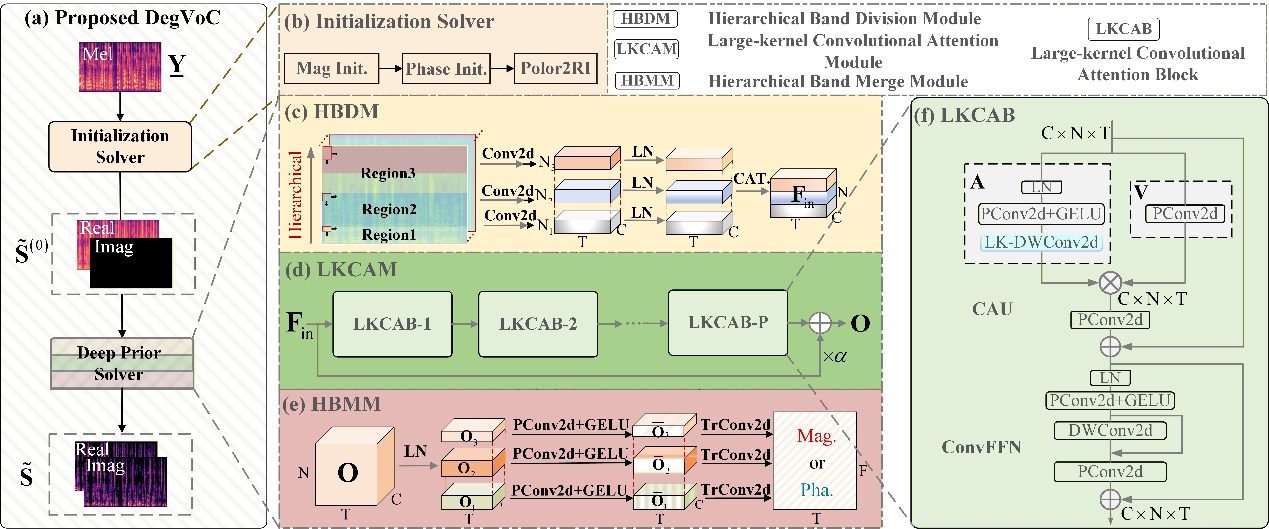
图1 提出的DegVoC方法示意图(图/中国科学院声学研究所)
2. GOMPSNR: Reflourish the Signal-to-Noise Ratio Metricfor Audio Generation Tasks
信噪比(SNR)是音频质量评估中最经典、应用最广泛的客观指标。但在当前主流的生成式音频建模范式下,传统SNR及其变体普遍存在评价不准、可靠性不足等问题。为此,博士研究生代凌玲、研究助理李安冬、郑成诗研究员及李晓东研究员等通过系统性分析指出,相位距离度量失效是制约传统指标精度的关键。基于此,研究重构了评价框架,提出更鲁棒的新型指标GOMPSNR,并将其拓展为可用于模型训练的损失函数,形成“幅度引导相位优化”与“幅度-相位联合优化”两类新型优化目标。实验结果表明,GOMPSNR相比传统SNR具有更稳定、更贴合人耳感知的误差度量能力,所提出的损失函数可显著提升前沿神经声码器的生成质量,为音频生成任务的评价与优化提供了统一、高效的新工具。
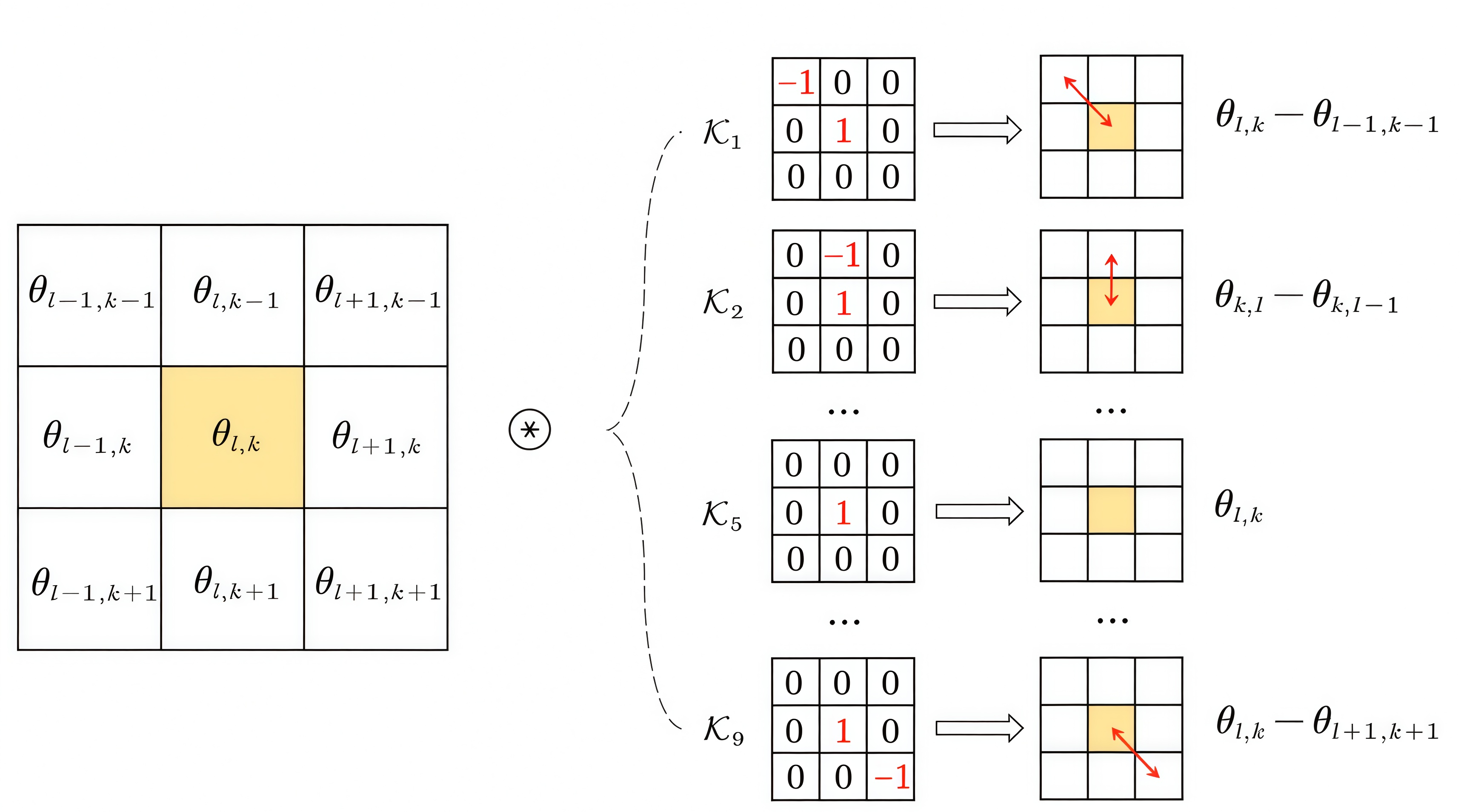

图2 提出的GOMPSNR示意图(图/中国科学院声学研究所)
3. SLD-L2S: Hierarchical Subspace Latent Diffusion for High-Fidelity Lip to Speech Synthesis
唇语语音合成(Lip-to-Speech)可直接从视觉唇动信号生成语音,在视频自动配音、无声通信、语音辅助等场景具有重要应用价值。现有方法常依赖梅尔谱或离散语义单元作为中间表征,前者易出现过平滑,后者会丢失细粒度声学细节,难以支撑高保真语音生成。为此,中国科学院声学研究所梁益帆博士生、特别研究助理李安冬及郑成诗研究员等提出分层子空间潜扩散框架SLD-L2S,摒弃传统声学表征,直接在连续潜空间中建立视觉唇动到神经音频编解码器隐变量的映射,有效避免量化误差与信息损失;同时采用子空间分解策略,将高维视觉特征解耦到多个平行子空间进行高效交互,更精准地建模跨模态时空依赖关系。此外,团队结合重参数化流匹配技术,引入语义一致性与语音语言模型双重辅助损失,在潜空间与波形层面同时约束生成过程。模型仅需10步推理即可完成高质量语音生成,在多项标准评测集上在取得了当前最优的合成语音质量。
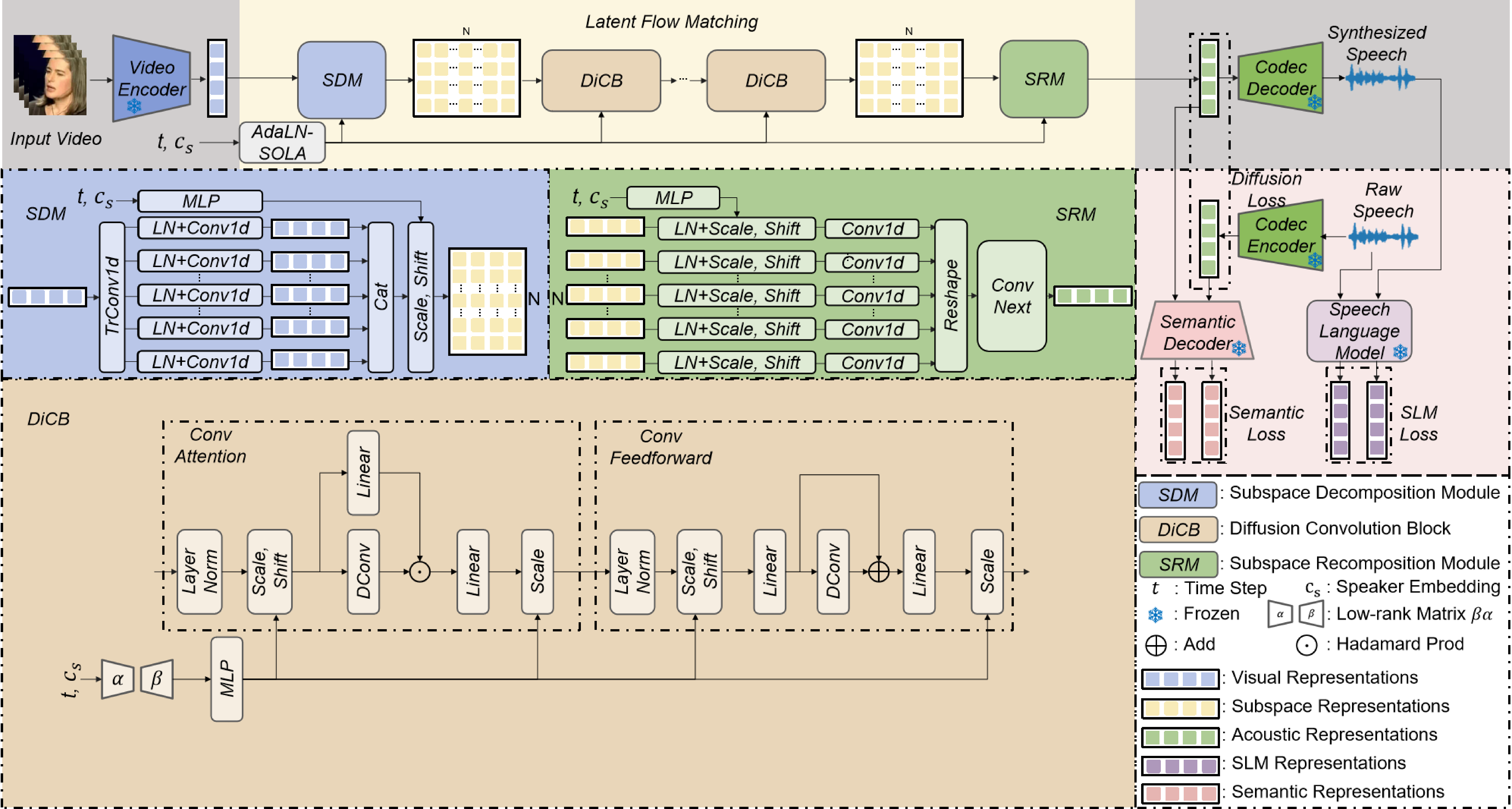
图3 提出的SLD-L2S方法示意图(图/中国科学院声学研究所)
关于AAAI:AAAI是人工智能领域的著名国际会议,也是中国计算机学会(CCF)推荐的A类会议。自1979年创办以来一直深受全球学者的广泛关注和认可,在计算机科学和人工智能领域具有崇高的声誉。本次一共有23680篇有效投稿,录用率仅17.6%。
参考文献:
LI Andong; LEI Tong; DAI Lingling; LI Kai; CHEN Rilin; YU Meng; LI Xiaodong; YU Dong; ZHENG Chengshi*. DegVoC: Revisiting Neural Vocoder from a Degradation Perspective. In Proc. AAAI 2026.
DAI Lingling; LI Andong*; CHI Cheng; LIANG Yifan; LI Xiaodong; ZHENG Chengshi*. GOMPSNR: Reflourish the Signal-to-Noise Ratio Metric for Audio Generation Tasks. In Proc. AAAI 2026 (in Press)
LIANG Yifan; LI Andong; YANG Kang; YU Guochen; LIU Fangkun; DAI Lingling; LI Xiaodong; ZHENG Chengshi*. SLD-L2S: Hierarchical Subspace Latent Diffusion for High-Fidelity Lip to Speech Synthesis. In Proc. AAAI 2026.