

近日,中国科学院声学研究所(以下简称声学所)噪声与音频声学实验室郑成诗研究员研究团队在听觉领域期刊Trends in Hearing (中国科学院期刊分区一区top)发表综述:Sixty Years of Frequency-Domain Monaural Speech Enhancement: From Traditional to Deep Learning Methods (时频域单通道语音增强60年——从传统方法到深度学习方法)。声学所郑成诗研究员、英国剑桥大学教授Brian C. J. Moore和声学所博士研究生罗笑雪为该综述共同一者,郑成诗研究员为论文通讯作者,声学所噪声与音频声学实验室为论文第一单位。该综述全面概述了时频域单通道语音增强60年发展历程的传统方法和深度学习方法:首先总结和分析了两类方法的基本假设,阐明了各自的优势和局限性;接着,使用相同的语料库比较两类共计十余种有代表性的方法处理性能,通过客观评价方法评估了不同方法对正常听力人群和听力受损人群的不同作用;最后总结了现有单通道语音增强方法在助听领域应用所面临的挑战及未来发展趋势。

近60年,研究人员对时频域单通道语音增强技术进行了广泛的研究。早期由于计算性能限制和浅层神经网络泛化能力较弱,对时频域单通道语音增强技术的研究主要集中于传统信号处理的方法。大量的经典传统方法被提出并成功应用于许多音频设备中。近十年来,随着深度学习的出现和发展,神经网络建模能力和泛化性能的提升,单通道语音增强技术性能实现了较大的飞跃。虽然目前已有许多关于传统方法或深度学习方法的综述论文和书籍出版,但这些综述并未将两类方法进行综合分析,也未深入揭示两类方法的各自优缺点,同时也没有对目前主流的时频域单通道语音增强技术进行同数据集下的综合性能比较。
在本综述中,研究人员回顾了过去六十年来提出的许多具有代表性的时频域单通道语音增强方法。其中,传统单通道语音增强方法的流程图如图1所示。传统方法通常不是数据驱动的,往往依赖于语音和噪声的特定统计模型和/或语音的确定性模型。本综述主要从传统语音增强算法可能使用的各模块入手进行梳理总结。其主要包括:噪声估计、先验信噪比估计、语音存在概率估计、谱增益估计、相位处理等。对于大多数传统的频域语音增强方法来说,有四个基本假设:第一,语音和噪声在统计上是独立的;第二,噪声比语音更平稳;第三,在特定统计模型下推导频谱增益函数时,每个时频点频谱在统计上相互独立;第四,语音相位不如语音幅度谱重要。仅有第一个假设是合理的,其他三个假设并不合理,这也就限制了传统算法的应用场景,并约束了基于这些假设的方法的性能上限。
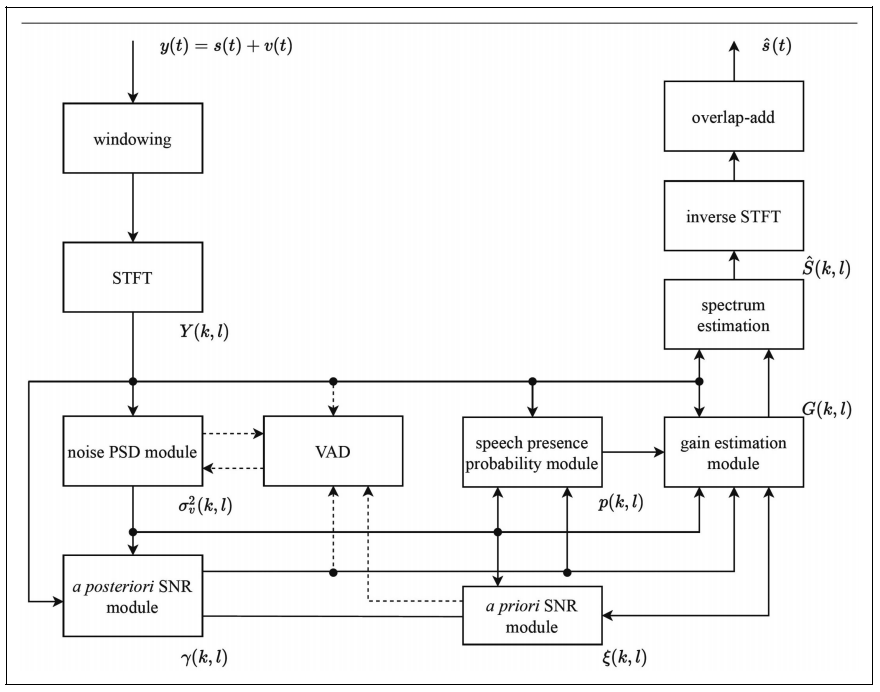
图1 传统单通道语音增强方法的流程图。(图/中国科学院声学研究所)
相比之下,深度学习方法通常由数据驱动,其性能取决于训练数据集、提供的输入特征、学习目标和深度学习网络架构。基于深度学习的单通道语音增强方法的基本流程图如图2所示。这类方法通常包括两个阶段:训练和测试。本综述对两个阶段中可能使用的模块分别进行了梳理总结,其分别为:特征提取、网络结构、学习目标和损失函数。值得一提的是,由于基于深度学习的单通道语音增强方法是由数据驱动的,这一"黑箱"性质侧面反映了这些深度学习方法的一个缺点:研究人员很难详细了解深度学习是如何实现其结果的,也很难解释改变 深度学习架构所产生的性能变化。
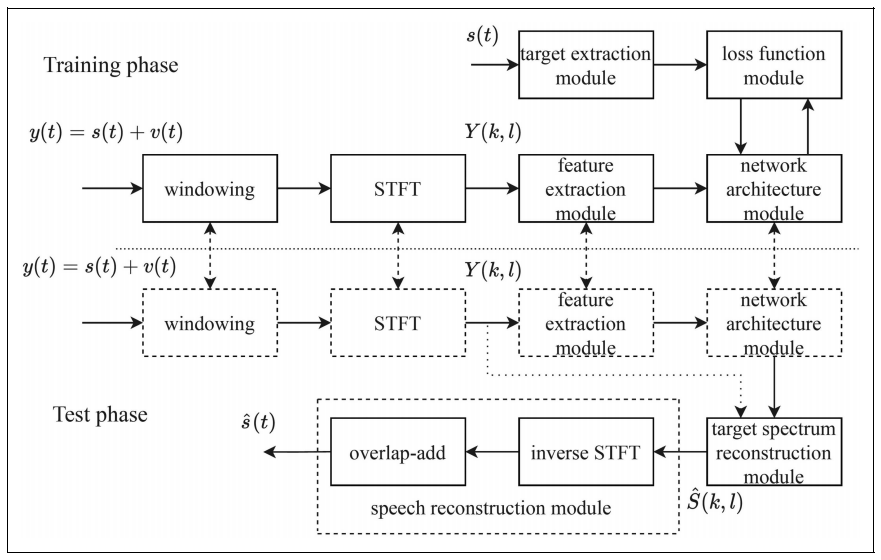
图2 基于深度学习的单通道语音增强方法的流程图。(图/中国科学院声学研究所)
尽管传统方法和深度学习方法截然不同,但后者深受前者的影响。此外,还有一些深度学习与传统方法融合的混合方法(Hybrid Method),通过深度学习直接映射传统方法需要的关键参数,例如语音和噪声的功率谱估计和先验信噪比估计等。这些混合方法综合传统算法和深度学习算法的优势,可以在相对有限的计算资源下达到一个较好的性能。
不同听力受损人群对算法设计需求往往也不同,本综述使用 WSJ + DNS和 Voice Bank + DEMAND 数据集对一些传统和深度学习的典型方法进行了综合评估,对两类代表性方法的性能进行直观统一的比较。本综述采用了与正常听力人群和听力受损人群相关的客观指标(HASQI和HASPI)对两类方法进行了综合测试,客观测试结果表明:
随着听力损失的增加,语音质量会提高,而语音可懂度会降低;
输入特征的压缩对模拟正常听力人群重要,但对模拟听力受损人群并不重要;
对于模拟正常听力/听力受损人群,基于深度学习的方法处理结果都相较传统算法有更好的性能体现。
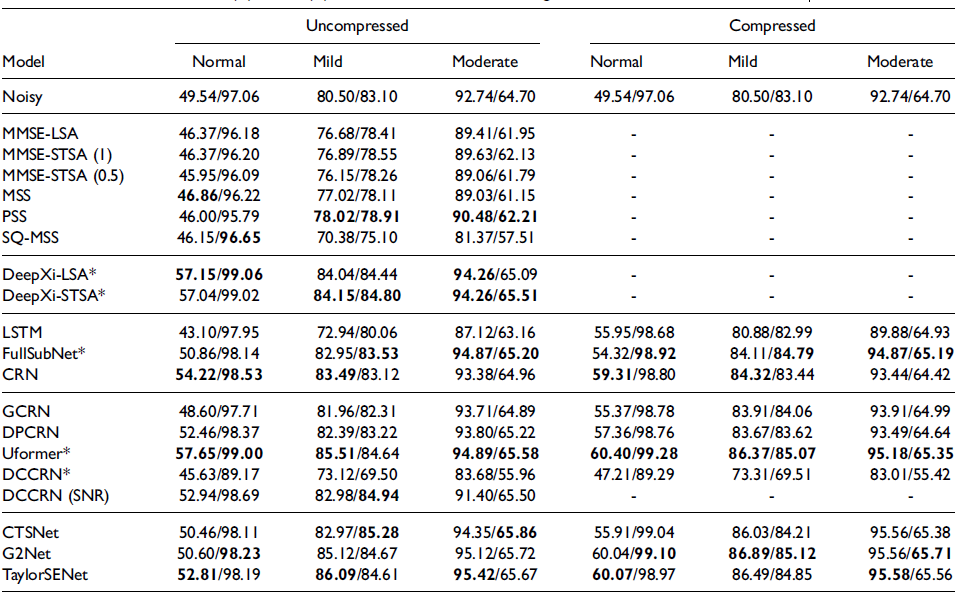
图3 Voice Bank + DEMAND 数据集下不同方法的HASPI(%)和HASQI(%)得分。(图/中国科学院声学研究所)
本综述回顾了过去六十年来提出的许多具有代表性的时频域单声道语音增强方法,主要包括传统信号处理方法和基于深度学习的方法。未来可研究探索的挑战和方向包括:1)研究具有可解释内在机制的深度学习单通道语音增强算法;2)结合传统算法降低深度学习方法的复杂度、存储量、时间延迟;3)开展听力正常人群和不同听力受损人群的主观测评工作。
本研究得到国家重点研发计划项目(No.2021YFB3201702)资助。
关键词:
语音增强;语音去混响;多阶段学习;噪声估计;深度复数网络
参考文献:
Zheng, C., Zhang, H., Liu, W., Luo, X., Li, A., Li, X., & Moore, B. C. (2023). Sixty years of frequency-domain monaural speech enhancement: From traditional to deep learning methods. Trends in Hearing, 27, 23312165231209913. DOI: 10.1177/23312165231209913
论文链接:
https://journals.sagepub.com/doi/full/10.1177/23312165231209913
相关开源代码链接:
https://github.com/cszheng-ioa/Sixty-years-of-frequency-domain-monaural-speech-enhancement