端对端语音识别是一种利用深度学习模型将语音信号直接转变为文字的技术,其中基于注意力机制的模型可以达到较高的识别准确率。但是大多数注意力机制模型需要完整的语音信号,不适用于在线处理语音流。
针对在线语音识别的应用场景,中科院语言声学与内容理解重点实验室的博士生缪浩然与其导师张鹏远研究员、程高峰助理研究员等人针对主流注意力机制处理语音流的性能开展研究,提出了一种单调截断语音流的在线注意力机制和一套高效实时的解码算法。
相关研究成果2020年4月在线发表于学术期刊 IEEE/ACM Transactions on Audio, Speech, and Language Processing 。
研究人员指出,语音识别系统对各时刻语音信号注意力的权重分布呈指数衰减态势,不利于处理长时语音流。他们还发现在线注意力模型训练和推理之间存在差异,从而导致模型性能下降。基于上述问题,研究人员在设计单调截断语音流的在线注意力模型时,优化了注意力权重指数衰减的特性,同时通过离散化注意力权重缩小训练和推理之间的差异。
基于公开的中英文语音识别数据集的实验表明,单调截断语音流的在线注意力模型在处理长时语音流时性能更加稳定。基于注意力机制和联结主义时序分类准则的联合在线解码算法,在线语音识别系统的字错误率略高于离线系统,其解码速度可以达到离线系统的1.5倍。
这种单调截断语音流的在线注意力机制和相关解码算法为端对端语音识别技术在大规模工业在线产品中的应用提供了可行方案。
此项研究得到国家自然科学基金(No.11590774,11590772,11590770)的资助。
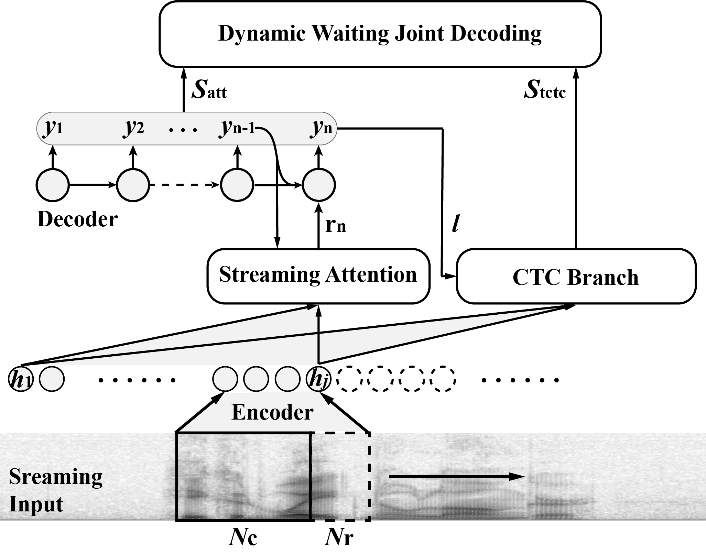
在线端对端语音识别框架(图/中科院声学所)
关键词:
端对端语音识别;在线语音识别;注意力机制
参考文献:
MIAO Haoran, CHENG Gaofeng, ZHANG Pengyuan, YAN Yonghong, Online Hybrid CTC/Attention End-to-End Automatic Speech Recognition Architecture. IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 1452-1465, 2020, DOI: 10.1109/TASLP.2020.2987752.
论文链接:
https://ieeexplore.ieee.org/document/9072325

