在语音通讯中,如何在抑制背景噪声的同时避免引入不自然的失真是一个重要的课题。目前基于深度学习的语音增强方法能够有效减少背景噪声成分,但是在噪声失配条件下会引入较多不自然的残差噪声,对语音舒适度造成较大影响。
对此,中科院噪声与振动重点实验室研究生李安冬与其导师郑成诗研究员等人提出了一种带有残差噪声控制的语音增强方法用于语音通讯,在人为保留较低背景噪声的前提下,以噪声抑制与语音失真最小化为目标进行联合优化,提高语音舒适度。
相关研究成果2020年4月在线发表于国际学术期刊 Applied Sciences 。
研究人员通过引入多个可调节参数推导出一种广义损失函数。用不同参数组合,使得增强后的语音在这两个目标间进行有效权衡。同时通过人为引入较低的背景噪声参与优化,能够有效增强语音的主观听觉质量。
实验结果表明,通过选择合理的参数组合,可使增强后的语音在客观指标与主观评估结果上优于以往的处理结果。
许多常用的损失函数均可被视为这种广义损失函数的特殊情况并用上述方法进行优化。这种增强方法可应用于语音通信设备中的噪声抑制与语音信息提取。
本研究得到了国家自然科学基金(No.61571435, 61801468,11974086)资助。
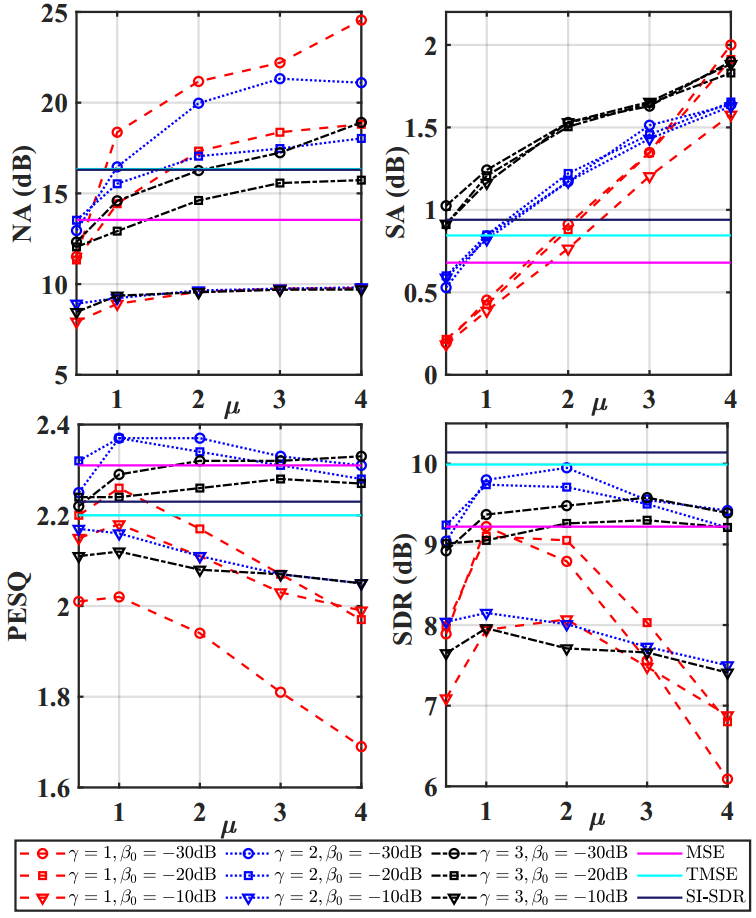
不同参数组合的客观指标对比(图/中科院声学所)
关键词:
广义损失函数;残差噪声控制;噪声整形;语音失真;深度学习
参考文献:
LI Andong, PENG Renhua. ZHENG Chengshi, LI Xiaodong. A Supervised Speech Enhancement Approach with Residual Noise Control for Voice Communication. Applied Sciences, 2020, 10, 2894. DOI:10.3390/app10082894
论文链接:
https://www.mdpi.com/2076-3417/10/8/2894#cite

