在复杂的声学应用场景中,语音信号容易受到环境噪声与房间混响的影响,给自动语音识别和语音通信带来较大的干扰。尽管目前基于深度学习的单通道语音增强方法能够有效抑制干扰成分,但这些方法的网络参数量较大且运算复杂度较高,难以应用于低功耗设备。
对此,中科院噪声与振动重点实验室研究生李安冬与其导师郑成诗研究员等人提出了一种基于卷积循环的单通道渐进语音增强方法,在保持增强性能不变的前提下,大幅度减小了参数量并降低了运算复杂度。
相关研究成果2020年4月在线发表于国际学术期刊 Applied Acoustics 。
研究人员在卷积循环神经网络基础上将增强过程分解为多个子阶段,在每个子阶段中进行轻量级模块建模并提升一部分语音的信噪比,从而在后续阶段中能够把之前阶段的输出作为先验信息,逐步提升后续处理结果。同时通过在不同阶段复用LSTM (Long and Short-Term Memory)模块的方式大幅度减小参数量。
实验结果表明,在仅采用3个阶段的情况下便可以达到和原有复杂卷积循环神经网络模型相近的性能。随着阶段数的增加,性能则会进一步提升。
这种增强方法可用于低功耗设备上的噪声抑制与语音信息恢复。
本研究得到了国家自然科学基金(No.61571435,61801468,11974086)资助。
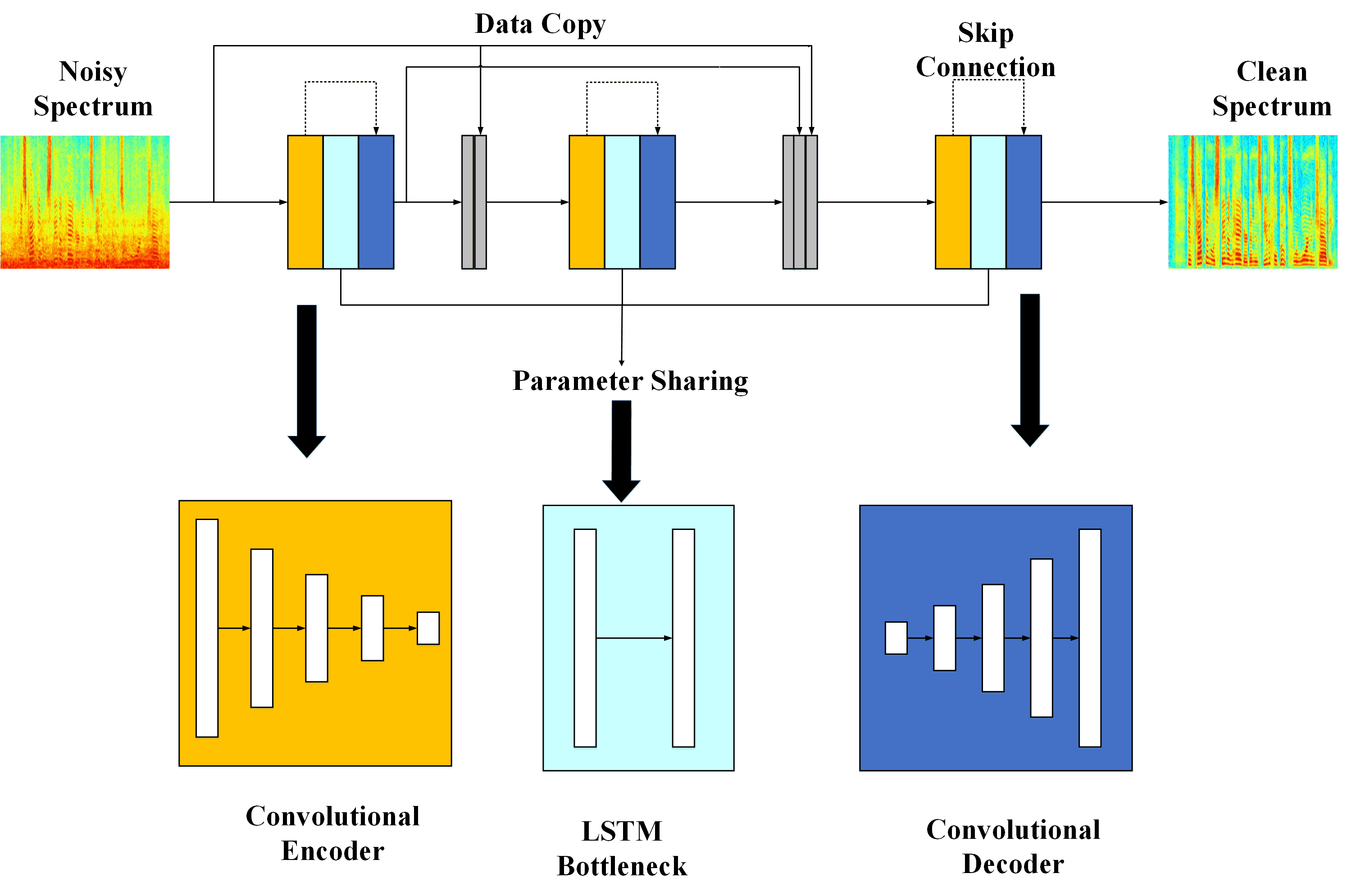
算法系统框图(图/中科院声学所)
关键词:
语音增强;深度学习;渐进学习;卷积神经网络;长短时记忆
参考文献:
LI Andong, YUAN Mingming, ZHENG Chengshi and LI Xiaodong. Speech enhancement using progressive learning-based convolutional recurrent neural network. Applied Acoustics, 166, p.107347. DOI: 10.1016/j.apacoust.2020.107347
论文链接:
https://www.sciencedirect.com/science/article/abs/pii/S0003682X19309326

