在电话通信、智能交互等应用场景中,目标说话人的语音信号通常会受到噪声或其他说话人干扰,从而影响语音质量和语音识别率,这就是著名的“鸡尾酒会问题”。有效解决这个问题的方法之一是通过盲源分离从仅有的混合观测信号中分离出原始声源,但此计算方法复杂度高,给实际应用带来了较大的困难。
为降低盲源分离方法的计算复杂度,中科院噪声与振动重点实验室的康坊与其导师杨飞然研究员、杨军研究员提出了一种基于独立成分分析的低复杂度盲源分离方法,在保证分离性能不受影响的情况下,极大地降低了计算复杂度。
相关研究成果近期发表于国际学术期刊 Speech Communication。
人们将独立成分分析应用于每一个频点的混合信号进行声源分离。独立成分分析方法固有的顺序模糊性导致频间信号顺序混叠,分离后的信号需要进行顺序调整,但复杂的排序机制极大地增加了整体的计算复杂度。
本工作中,研究人员利用声源自身存在的频间依赖性,对不同频率间的分离信号做相关性分析来解决顺序模糊性问题。首先采用非迭代的方法对分离信号进行相邻频点排序,为防止错排结果传播,对可信度低的频点参照局部中心点进行顺序调整。局部排序的结果为全局聚类校正提供一个较优的初始化,仅需少量的迭代次数便可达到收敛效果。
实验结果表明,本方法的计算复杂度要远低于具有相同分离性能的其他分离方法。
这种低复杂度的盲源分离方法可用于语音交互、电话通信以及助听器设备等应用场景,提高语音质量和语音可懂度。
本研究得到国家重点研发计划(项目编2017YFC0804900),中国科学院青年创新促进会(2018027),中国科学院声学研究所青年英才计划项目(QNYC201812)和中国科学院先导专项项目(XDC02020400)资助。
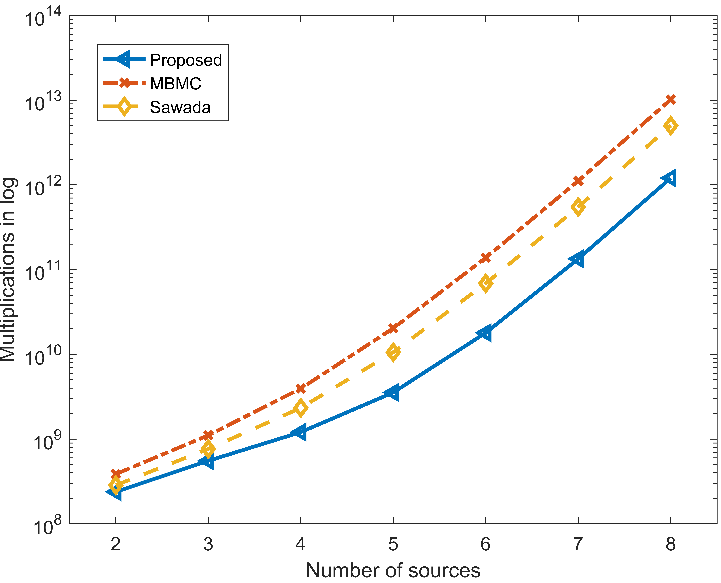
图1 计算复杂度对比(图/中科院声学所)
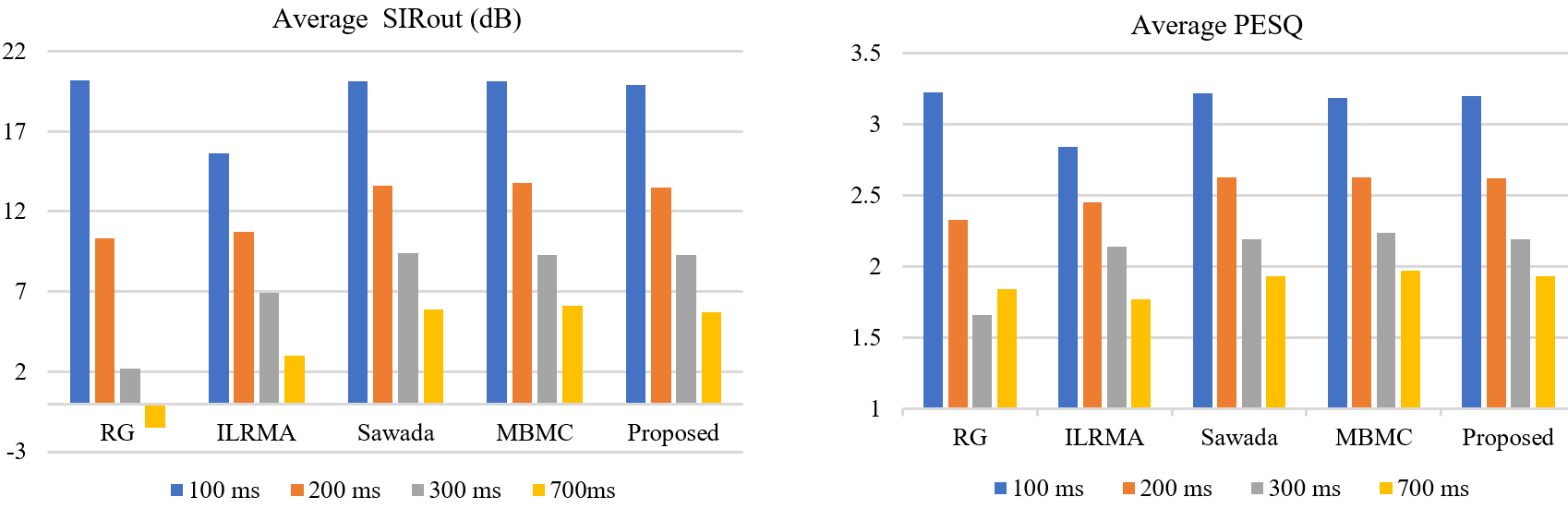
图2 不同混响时间下的分离性能对比(左)平均输出信干比与(右)平均PESQ得分(图/中科院声学所)
关键词:
频域盲源分离;顺序模糊性问题;局部排序;全局校正;计算复杂度
参考文献:
KANG Fang, YANG Feiran, YANG Jun. A low-complexity permutation alignment method for frequency-domain blind source separation. Speech Communication. 2019, 115: 88-94. DOI: 10.1016/j.specom.2019.11.002.
论文链接
https://doi.org/10.1016/j.specom.2019.11.002

